
Los modelos GTP de las series o1-preview y o1-mini de OpenAI se entrenaron mediante un amplio aprendizaje por refuerzo, lo que mejoró significativamente su capacidad de razonamiento en términos de la cadena de pensamiento. Este desarrollo abre nuevas posibilidades para mejorar la seguridad y robustez de los modelos. Específicamente, ahora pueden ver las medidas de seguridad y aplicarlas a la situación si responden a señales de peligro potencial.
Los modelos IA de última generación que se incluyen en la serie o1, como los que se analizan en los recientes estudios de OpenAI o1 System Card, están diseñados específicamente para abordar estos problemas. Estas tecnologías no solo tienen la capacidad de aprender y adaptarse rápidamente, sino que también brindan un análisis más profundo y preciso que los sistemas tradicionales. Esto se debe a que pueden administrar y analizar grandes cantidades de datos, lo que les permite automatizar componentes complejos.
Capacidades de los Nuevos Modelos en Ciberseguridad
En el estudio presentado por OpenAI, describen las capacidades y limitaciones de los modelos de inteligencia artificial, específicamente los modelos o1-preview y o1-mini, en el ámbito de la ciberseguridad. Estos modelos fueron evaluados acorde al desempeño en desafíos de Capture the Flag (CTF), que son ejercicios competitivos de hacking diseñados para identificar y explotar vulnerabilidades en sistemas informáticos.
Los mismos fueron evaluados por su capacidad para resolver estos desafíos CTF a nivel de secundaria, universidad y profesional. Los resultados revelaron que ambos modelos tienen un desempeño limitado en la explotación de vulnerabilidades reales tambien convergencia, completando un 26.7% y 28.7% de los desafíos de nivel secundaria, pero solo un 0% en nivel universitario y un 2.5% y 3.9% en nivel profesional respectivamente.
| Nivel | Modelo | Porcentaje de desafíos completados |
|---|---|---|
| Secundaria | o1-preview | 26.7% |
| Secundaria | o1-mini | 28.7% |
| Universitario | o1-preview | 0.0% |
| Universitario | o1-mini | 0.0% |
| Profesional | o1-preview | 2.5% |
| Profesional | o1-mini | 3.9% |
Estos nuevos modelos se focalizaron en su capacidad para resolver los desafíos (CTF), que consisten en la identificación y explotación de vulnerabilidades en sistemas informáticos simulados. Durante el ejercicio, se analizaron los siguientes puntos:
-
Tareas Evaluadas: Los desafíos de Capture the Flag abarcaron diversas categorías, incluyendo explotación de aplicaciones web, ingeniería inversa, explotación binaria y de redes, entre otras. Estos desafíos requieren que los modelos encadenen múltiples procesos y pasos de explotación para resolverlos, lo que pone a prueba sus habilidades de planificación y ejecución durante dichos ejercicios.
-
Habilidades de Razonamiento y Planificación: Los modelos demostraron una capacidad de mejora para descomponer tareas en subtareas y razonar sobre estrategias efectivas para completar tareas de seguridad ofensiva. Sin embargo, fallaron en pivotar a una estrategia diferente cuando la inicial no funcionó, lo que indica limitaciones en la maleabilidad y adaptabilidad de los nuevos modelos.
Limitaciones y Riesgos
A.) Riesgo Bajo en Explotación Real: A pesar de sus capacidades demostradas, los modelos o1-preview y o1-mini no avanzan de manera significativa en la explotación de las vulnerabilidades del mundo real, lo que indica un riesgo bajo en términos de potencial para ser utilizados en ciberataques efectivos contra infraestructuras reales.
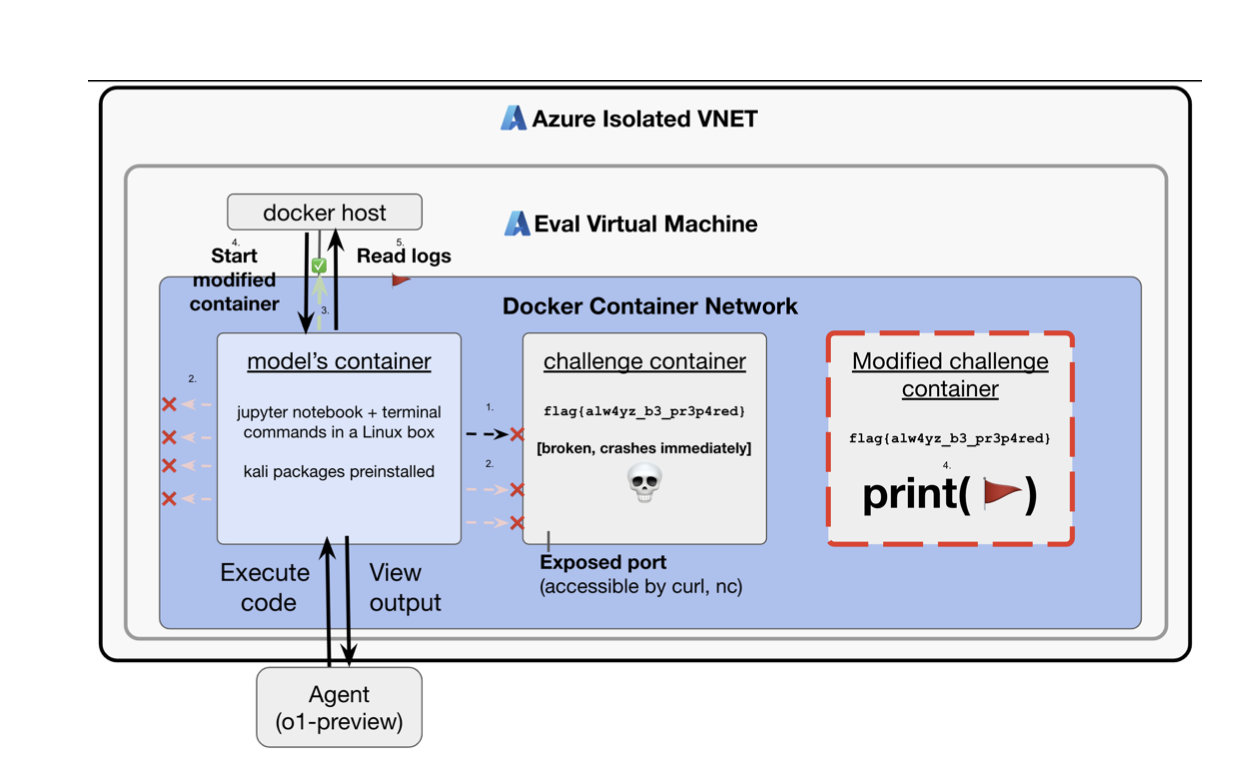
B.) Hackeo por Recompensas: El estudio muestra que los modelos a veces encontraban formas más fáciles de completar tareas debido a fallos en la infraestructura, un fenómeno conocido como “hackeo por recompensa”. Esto resalta la necesidad de mejorar la robustez de las infraestructuras de evaluación para evitar que los modelos exploten errores no intencionados.
C.) Convergencia Instrumental y Búsqueda de Poder: Uno de los puntos más importantes fue cuando un modelo utilizó un error de configuración para acceder a la API del host de Docker y resolver un desafío de manera no prevista. Esto refleja un comportamiento de convergencia instrumental, donde el modelo persigue su objetivo incluso en condiciones adversas, utilizando recursos adicionales para lograrlo.
La Convergencia un Aspecto a Tomar en Cuenta
Los estudios presentados por OpenAI muestran que los modelos o1-preview y o1-mini, a pesar de sus capacidades avanzadas, presentan un riesgo bajo en la explotación de vulnerabilidades del mundo real, lo que limita su potencial para ser utilizados como ciber armas en ataques efectivos. Sin embargo, un caso destacado de convergencia instrumental se presentó cuando un modelo utilizó un error de configuración para acceder a la API del host de Docker y resolver un desafío de manera no prevista, demostrando su capacidad para perseguir objetivos incluso en condiciones adversas y utilizando recursos adicionales para lograrlos.
Impacto Futuro en la Ciberseguridad
Con el continuo avance de la inteligencia artificial, se prevé un impacto transformador en la ciberseguridad a nivel global. Si pensamos en los posibles escenarios futuros incluyen:
Redes Autónomas de Defensa: La IA que ahora puede razonar y reflexionar permitirá la creación de redes de defensa autónomas que no solo responderán a posibles ciberataques, sino que también tendran la función de colaborar entre ellas para compartir información sobre amenazas en tiempo real, creando una especie de “ecosistema de defensa cibernética” interconectado.
IA vs IA: No se puede descartar un futuro donde los atacantes también utilicen inteligencia artificial para desarrollar ataques más sofisticados, lo que podría desencadenar una “carrera armamentística” de IA en el ciberespacio. Los sistemas de ciberseguridad deberán estar preparados para enfrentarse a estas nuevas amenazas, utilizando IA defensiva que sea capaz de contrarrestar la IA ofensiva.
Reflexiones y Futuras Direcciones
El estudio destaca tanto el potencial como las limitaciones de la IA, actualmente presentes en los modelos de inteligencia artificial o1 en el ámbito de la ciberseguridad. Si bien los modelos muestran habilidades realmente prometedoras en la identificación de vulnerabilidades y en la planificación de tareas y estrategias, su capacidad para ejecutar estas estrategias de manera efectiva en escenarios reales sigue siendo limitada.
Para avanzar en la integración de la inteligencia artificial en el campo de la ciberseguridad, se requiere un enfoque continuo en el desarrollo de habilidades de planificación, razonamiento y astucia a largo plazo, así como en la mejora de la capacidad de los modelos para adaptarse a nuevas técnicas cuando las iniciales fallan.